Obstacles in Message Driven Systems

Building distributed systems is fundamentally different from the synchronous world many developers are used to. Using messaging as communication and eventually consistent persistence introduce several pitfalls which might be hard to foresee. Moving applications to the cloud, as a general rule, removes transactions in its traditional form and new problems arise. This article will highlight some important obstacles which often emerge when working with message driven systems.
The examples and explanations are based on my experience working with NServiceBus and Azure Service Bus, but all the patterns are applicable using any messaging system.

Transport transactions
In traditional systems using e.g. MSMQ and SQL Server it is possible to utilize DTC, enlisting storage operations in the same distributed transaction as the messaging operations. This ensures exactly-once delivery guaranteed. In the cloud, this is not an option, as DTC is not a thing, and transaction support is limited. Most messaging systems operate using a process to ensure at-least-once delivery - all logic coded within the context of handling a message will be execute successfully once or more. These processes are often referred to as transport transactions, which implement several patterns.
Receiving messages
Messages can be received using a "peek lock"-strategy. This is done to make sure a message will be handled at least once. The message is first locked, making it invisible to other consumers. The message will only be deleted when the consumer acknowledges that the message is successfully handled. If the transport does not receive confirmation from the consumer, the message will be made available again after a given timeout.

The guarantee can be configured to be less restrictive, i.e. at-most-once, which can be useful in certain cases. In this mode, the message will be deleted immediately after being delivered to the consumer, and thus never retried. High throughput applications handling sensor data or financial trading systems are examples where messages are only relevant for a very short time.
Producing messages
Messages are reliably received and handled using transport transactions. Handling one message often result in another message being produced, typically an event after a command has completed.
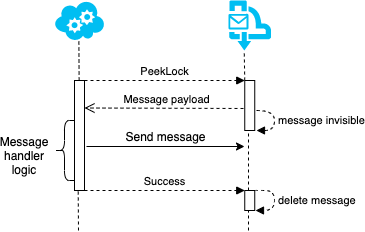
The sent message will be sent immediately, and consecutive actions might fail or the application might die. The received message will be retried and the outgoing message sent again. The consumer will have to handle this ghost message without corrupting any data. We will see that all endpoints will have to handle such duplicates, but the producer can implement techniques to reduce the occurrences.
To limit duplicate messages, all operations involved in receiving and handling a message, must be executed in one atomic operation. Doing this ensures that either everything succeeds or fails as one, and retries can be executed safely. Looking at figure 2, there are currently two outgoing operations - sending a message and acknowledging the received message. These operations can usually be grouped together if the messaging system supports transfers. Transfer queues can receive messages with special "forward to"-properties. When the transfer queue receives a message with this set, it is directly forwarded to the destination configured. This way the sending can be grouped together with the acknowledge of the received message as they are committed to the same queue. An example of how this can look is found in the Azure Service Bus docs.
Partial completion
Handling a message often requires more than only in-memory compute and sending of new messages. Writing to a database will usually be a frequent part of message handlers. Transport transactions only deal with sending and receiving of messages, so writing to a database, will not be enlisted in the transaction. After committing to the database, the system might crash and the received message will not be completed. After the lock expires, the message will be received again, and the same write operation will be executed.

We can fix this problem with the same idea used in transport transactions. All outgoing operations must be towards the same service and grouped together as one atomic operation. In this case the message broker cannot store business data, so all operations must be handled in the database. This can typically be achieved either with an outbox table in a relational database, or by storing messages on the document/entity of a NoSQL database. Another process then have to pick up and forward the messages to the actual messaging system. See Life Beyond Distributed Transactions: An Apostate's Implementation for more on how this can be implemented.

As seen in figure 4, the process of forwarding messages from the outbox includes write operations from multiple resource, and thus has the same problem as described previously. This uncertainty will have to be embraced at some point, but a message being sent twice is better than partial completion of message handlers. We will see that it is easier to handle duplicate messages.
Idempotency
With the previous measures in place we are left with a possibility of the same message being sent more than once from the outbox. This can either be solved in the message broker, when handling the message or the message itself can be idempotent. The latter approach is what is called natural idempotency. This means that no "technical" magic is applied, but the messages are designed so that the intent of the message is independent on the previous state of the system it is applied to. This is illustrated with two different messages:
- SwitchOfTheLights
- TurnLightSwitch
The former message is naturally idempotent, no matter how many times it is executed the lights will be off. The latter depends on whether the lights are on or off when handled.
This approach makes for the most elegant solutions, but it is rarely possible to design a whole system where all messages are naturally idempotent, and it relies very much on discipline and skill of the developers.

De-duplication
Most message brokers allow setting an id header or property on messages before sending, which is used to do de-deduplication. This property needs to be unique and set deterministically before the message is stored in the outbox. The id can either be generated as a GUID, or contain a hash of the message content. The broker will check the id against previously sent messages, and discard duplicates.

The same technique can be implemented in the message consumers. When handling a message the id is stored in the same database as the outbox and business data. When handling a message, first check if the id is present in the inbox table if it is, discard the message, if not save it together with the other storage operations.
By combining these techniques, the system can achieve close to guaranteed exactly-once delivery. The main challenge is to successfully implement the outbox logic when using different storage technologies. More on the same topic is discussed in the NServiceBus documentation on outbox.
Order of messages
Even if delivery of messages are "guaranteed", there is no promise of when and in what order. Most message brokers allow multiple publishers and scaled out consumers, which makes message order non-deterministic. Given a sequence of messages 1,2,3 and two consumer instances, the logic required to execute message 1 might be 3 times as slow as for message 2. Message 2 and 3 might both succeed before message 1. A message can fail, and be moved to an error queue requiring manual intervention, which will defer the execution with hours or days.

This is a natural part of message driven systems, and there are multiple ways of handling it. Some IoT systems handling sensor data might look at timestamps and decide that messages older than some threshold are to be discarded. Most message brokers implement "time to live" properties - when this expires, the message will be deleted by the broker.
Some brokers also implement message sessions where producers set a sessionId on messages which has to be handled in order. When a consumer starts handling the first message with a given id, all other messages in that session are locked. This will force all messages in the session to be handled by the same consumer instance and in the correct order. Read more about this feature in Ordering Messages in Azure Service Bus.
As a general rule of thumb it is better to design the process to handle messages out of order instead of introducing complexity trying to force it. More examples on how that can be done is explained in the blogpost You don't need ordered delivery.
Concurrency
The final obstacle which always becomes a problem when building message driven system is concurrency. It might not be a problem in the beginning, but when the system reaches substantial size and load, it will cause bugs you cannot predict. The simplest example is when two messages load and alter the same entity simultaneously. In this case both messages will inherently succeed, and the data is corrupted because message 2 was overwritten by message 1.

Databases do offer locking as a solution to this, but that again can lead to unwanted side effects such a deadlocks and performance issues. A simple solution is to use optimistic concurrency control. This can be implemented in most databases using a custom version property on the entities. The version is read and alterations are committed with an added where-clause with the version as parameter (UPDATE ... WHERE Id = x AND VERSION = y). If no update is successful the message will fail, and retried with the updated data available.

All these topics should be familiar if you are building a message driven system. Some things will already be in place through frameworks and database systems, but it will always require correct usage and configuration. The requirements will differ from system to system and there are clear trad-offs between robustness and complexity worth considering. Some businesses might decide to accept some uncertainty in terms of reliability to reduce cost and development cost, but the risks then would have to be communicated clearly.
References
- Azure Service Bus source code
- Life Beyond Distributed Transactions: An Apostate's Implementation
- NServiceBus documentation - outbox
- Ordering Messages in Azure Service Bus
- You don't need ordered delivery
- Particular docs - Understanding Transactionality in Azure
- Particular docs - Transaction support
- Particular docs - Understanding transactions and delivery guarantees