Git Cooperation - From fancy to Functioning

Background
There are a lot of articles online about git and different approaches and strategies, and this often becomes a point of discussion when talking to colleges. There are all the Git[insert non-descriptive language]Flow and different types of pull request strategies, all trying to solve some kind of problem, a problem that probably should be non-existing. For some Git is a necessary evil, that should be abstracted away by some magic tooling doing all the work. Often a branching strategy is chosen pretty much at random without much though behind, it seems to end up being GitFlow. This might work for some teams, but as I see it, this type of branching model only makes it harder for those who is having a hard time with Git.
Git is a very powerful system, which when used correctly can provide much more than just source control. A proper maintained git log can tell the true story of how the service/system has evolved over time. This story can be read out between releases to generate a changelog, fed to analysis tools to identify maintenance problems or even used to find bugs using git bisect. For new developers to be able to scroll through the git log without seeing guitar hero patterns can be useful to get a overview of how the system is built. A linear history in combination with good commit messages makes the git log useful and beautiful!
|
|
Ground rules
How a team does branching should of course be tailored to how the team works and no model should be enforced without reasoning, though I recognize some basic principles that should always be enforced:
- More than one eternal branch is not necessary and should be avoided.
- Only one version of the code is maintained at a time, meaning no environment specific branches or similar.
- Every commit is built once, thus becoming a release candidate which might end up in production. (Typically after being tested and promoted through a series of environments, e.g. using a tool like Octopus Deploy).
- Developers rebase their work on top of the remote branch before pushing changes, keeping the history linear, resolving conflicts locally.
- The commit that is in production needs to be identifiable in some way, to enable hotfixing.
Improvement by simplification
I truly believe that the best way of improving any system, process or model is by removing unnecessary parts until you have the bare minimum to solve the problems at hand. I will use GitFlow as an example which is a normal starting point for many teams working with Git.
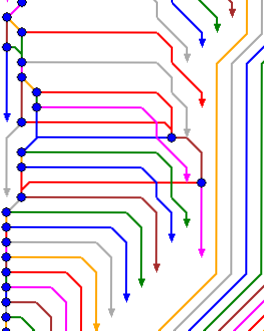
A visual example of GitFlow in one picture, including release branches and a hotfix inbetween can look something like this:
Getting ride of the "ghost branch"
The first thing that stands out is that there are too many branches, cluttering the readability, there isn't really one path to follow telling the truth about the life of the system. The master branch holds one commit per release which is supposed to fulfill requirement 5. On the contrary this strategy conflicts with requirement 3, since releases are merged to master when "finished", thus built again. I have seen this solved by promoting the commit that was built from development/release and never building from the master branch. This would be fine, but it is an unnecessary complex solution to a simple problem. All this can be avoided by only having one eternal branch (call it whatever), where commits are built, deployed, tested and finally released from, then tagged with a version number. When a hotfix is needed the commit that is in production can always be identified, as the last tagged revision (git describe can be used to locate this last tag).
If a verification period is desirable, a release branch could still be utilized. Release branches can be introduced by creating a release branch at the last commit before starting the verification period, same as for GitFlow. Since a branch in git simply is a pointer to a commit, nothing new would be built. During the verification period the team can continue to work on new features on master. When the release is ready, the commit which the release branch points to will be released to production and tagged, while the release branch is merged to master and deleted. During most releases there should be no changes required on the release branch, only exception being bug fixes found during verification. Having to do changes on the release branch on a consistent basis is an anti-pattern which should be avoided.
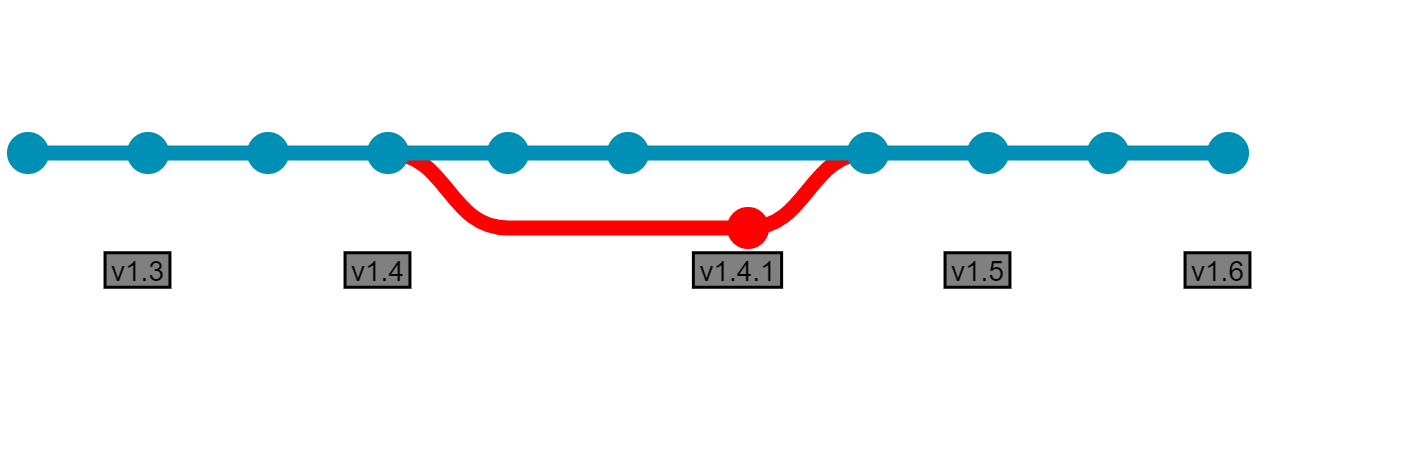
Bugs found in production are fixed on hotfix branches created from the last tagged commit. After fixing the bug, the new commit is tested, then tagged, merged and deleted in the same way as the release branches. By doing this we can keep a clean working branch, without leaving "dead" branches around.
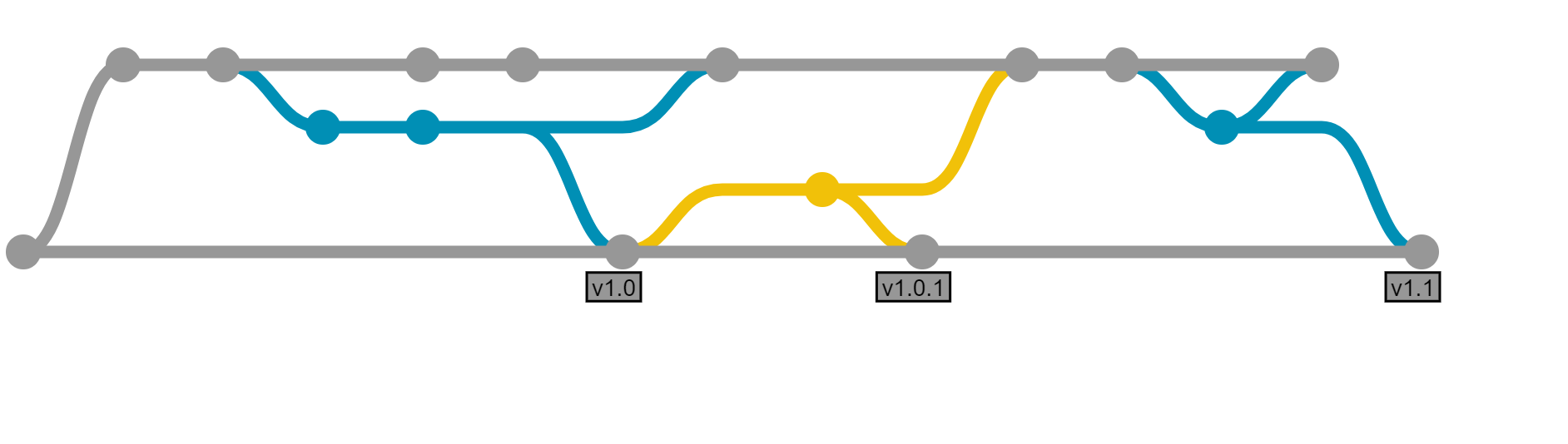
The same picture now looks like this:
Removing release branches
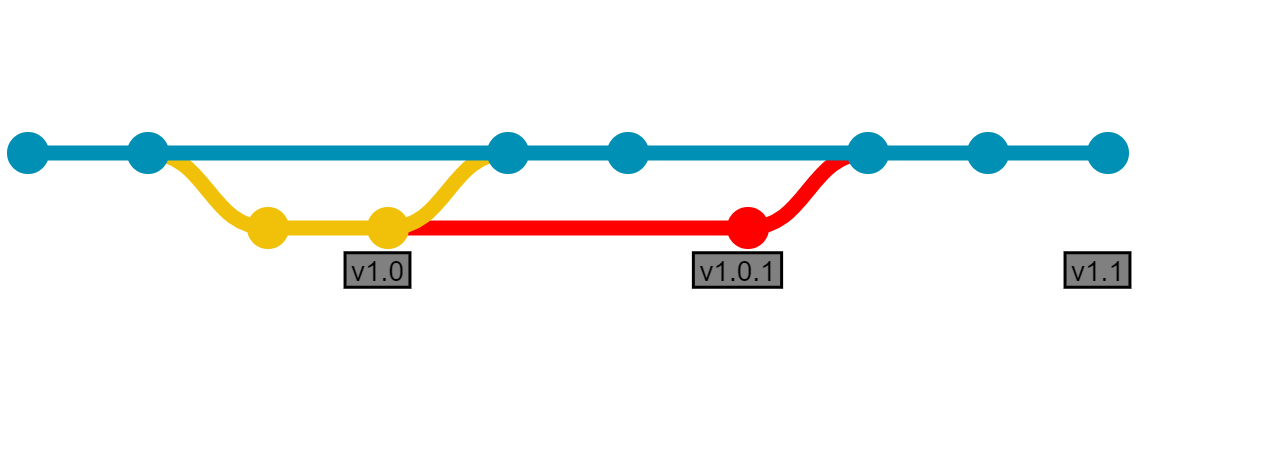
If releases are created frequently enough, and most of the time there are no changes required during the verification period, the release branches can be skipped all together. When a release is ready for verification, a tag is created and the commit promoted to the correct test environments, and finally to production. If a bug is found during verification, it can be fixed either as a hotfix from the tag, while development for the next release continues on master, or simple fixed on master and deployed as a new release. This keeps the number of branches, merges and concepts down to the bare minimum, allowing efficient and understandable integration between multiple contributors.
We end up with this picture, fulfilling all the same requirements as what we started with:
Summary
This walk-through shows how one can go from a quite complex branching model, to a simple one without compromising any functionality. Going from 2 eternal branches and striving towards removing the necessity for release branches makes it much easier to carry out a release or hotfix. The number of merges are kept to a minimum and tags are used to keep track of production code.
I do not mention feature branches or pull request, which I do think should be used when appropriate. If a commit is directly created by a developer or merged in from a feature branch as a PR does not conflict with the models described. Important is that all work supposed to end up in production must be committed on master to be included in a release later on.
The suggestions described in this post is based on personal experience during the last 2 years of working actively with git and frequently releasing to production. During the time I have been inspired by other articles discussing the same issue, such as:
- GitFlow considered harmful
- Follow up to GitFlow considered harmful
- Enabling Trunk Based Development with Deployment Pipelines
Trunk Base Development, which pretty much reassembles what I have concluded, has caught more attention lately. This way of working was mentioned by Damian Brady (formerly Octopus Deploy, now Microsoft) at NDC Oslo 2017, as an effective way of working with Git. He revealed that the team working on Microsoft's VSTS does continuous integration this way, using one branch where all the work goes, and "cutting" of releases when needed.
Later I will do a similar walk-through of how deployment and versioning can be automated in conjunction with this type of branching strategy.